Story-Driven Observability: Turning Tianji Dashboards into Decisions

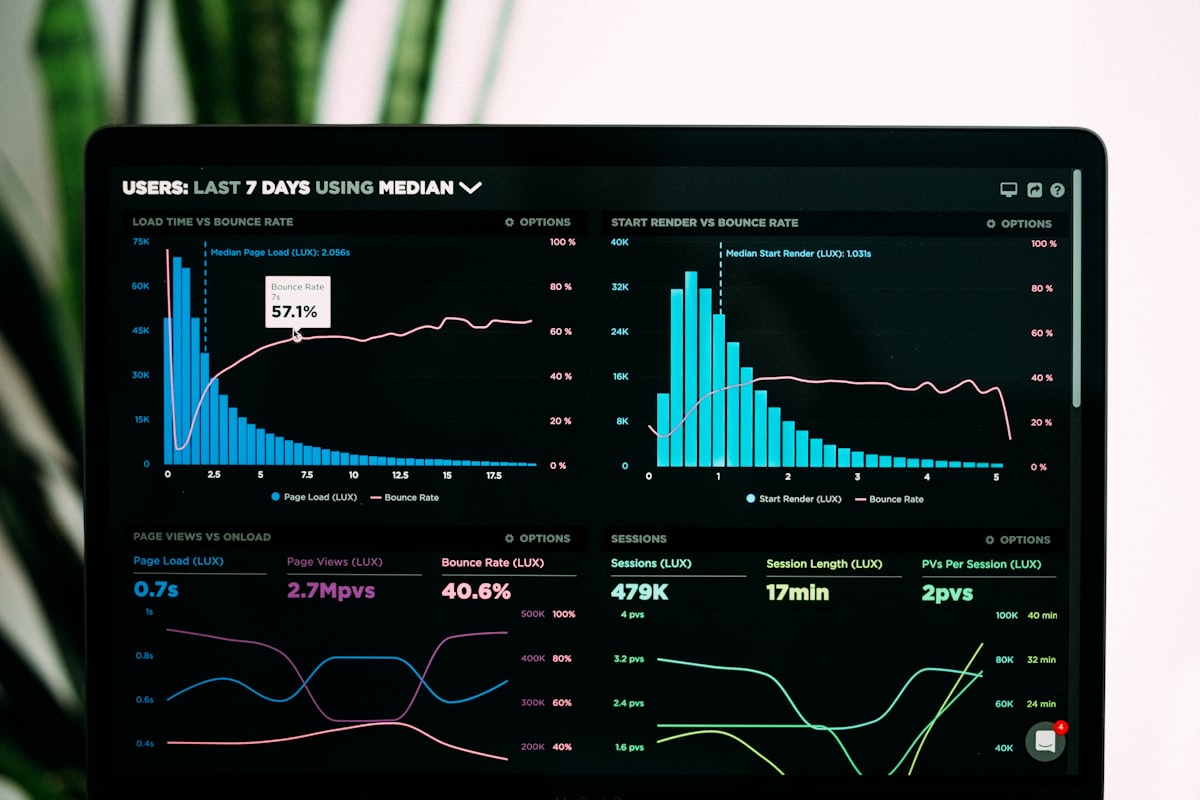
Organizations collect terabytes of metrics, traces, and logs every day, yet on-call engineers still ask the same question during incidents: What exactly is happening right now? Tianji was created to close this gap. By unifying website analytics, uptime monitoring, server status, and telemetry in one open-source platform, Tianji gives teams the context they need to act quickly.
From Raw Signals to Narrative Insight
Traditional observability setups scatter information across disconnected dashboards. Tianji avoids this fragmentation by correlating metrics, incidents, and user behavior in one timeline. When an alert fires, responders see the full story—response times, geographic impact, concurrent deployments, and even user journeys that led to errors.
This context makes handoffs faster. Instead of forwarding ten screenshots, teams can share a single Tianji incident view that highlights the relevant trends, suspected root causes, and user impact. The result is a shared understanding that accelerates triage.
Automating the First Draft of Postmortems
Tianji leverages AI summarization to turn monitoring data into human-readable briefings. Every alert can trigger an automated draft that captures key metrics, timeline milestones, and anomalous signals. Engineers can refine the draft rather than starting from scratch, reducing the time needed to publish reliable post-incident notes.
The same automation helps SRE teams run proactive health checks. Scheduled summaries highlight slow-burning issues—like growing latency or memory pressure—before they escalate. These narrative reports translate raw telemetry into action items that stakeholders outside the engineering team can understand.
Empowering Continuous Improvement
Story-driven observability is not only about speed; it also supports long-term learning. Tianji keeps historical incident narratives, linked to their corresponding dashboards and runbooks. Teams can review past incidents to see how similar signals played out, making it easier to avoid repeated mistakes.
That historical perspective informs capacity planning, reliability roadmaps, and even customer communications. With Tianji, organizations evolve from reactive firefighting to deliberate, data-informed decision making.
Getting Started with Tianji
Because Tianji is open source, teams can self-host the entire stack and adapt it to their infrastructure. Deploy the lightweight reporter to stream server status, configure website analytics in minutes, and integrate existing alerting channels. As coverage expands, Tianji becomes the single pane of glass that connects product metrics with operational health.
Ready to translate noise into narrative? Spin up Tianji, connect your services, and watch your observability practice transform from dashboard watching to decisive action.