Release‑aware Monitoring: Watch Every Deploy Smarter
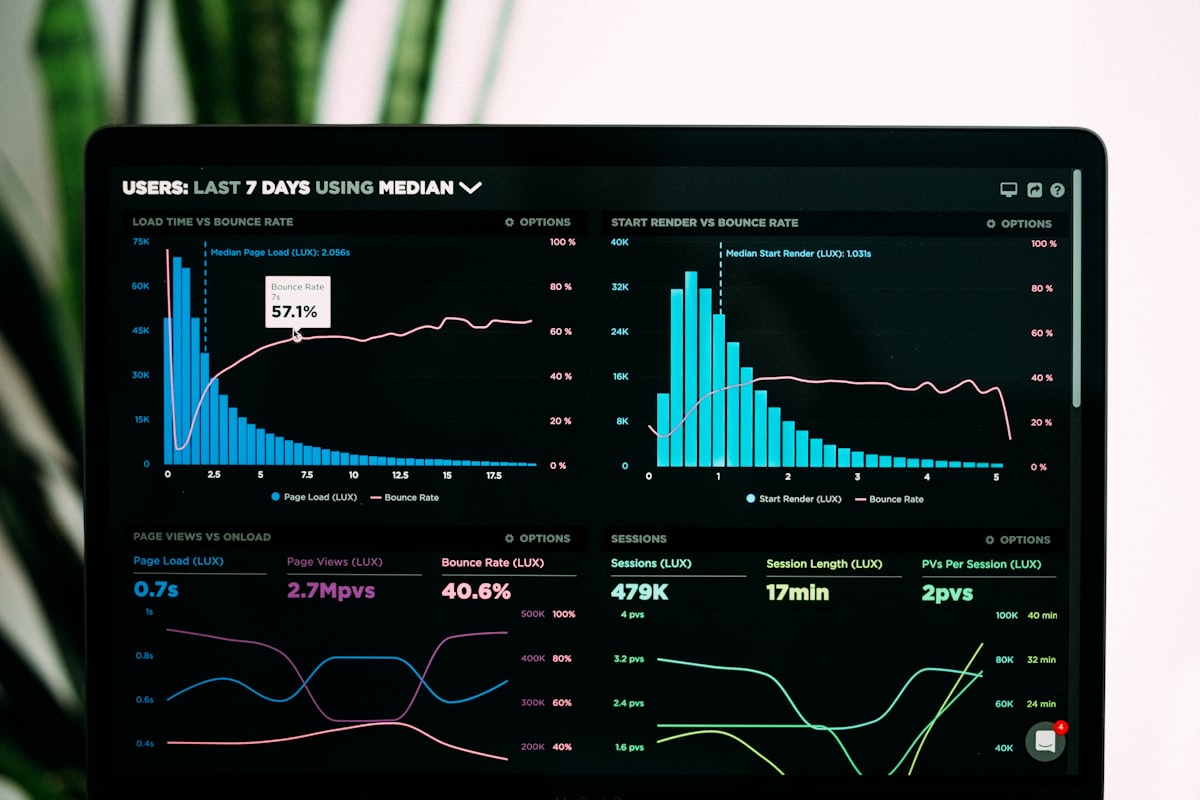
Most monitoring setups work fine in steady state, yet fall apart during releases: thresholds misfire, samples miss the key moments, and alert storms hide real issues. Release‑aware monitoring brings “release context” into monitoring decisions—adjusting sampling/thresholds across pre‑, during‑, and post‑deploy phases, folding related signals, and focusing on what truly impacts SLOs.
Why “release‑aware” matters
- Deploys are high‑risk windows with parameter, topology, and traffic changes.
- Static thresholds (e.g., fixed P95) produce high false‑positive rates during rollouts.
- Canary/blue‑green needs cohort‑aware dashboards and alerting strategies.
The goal: inject “just released?”, “traffic split”, “feature flags”, and “target cohorts” into alerting and sampling logic to increase sensitivity where it matters and suppress noise elsewhere.
What release context includes

- Commits/tickets: commit, PR, ticket, version
- Deploy metadata: start/end time, environment, batch, blast radius
- Traffic strategy: canary ratio, blue‑green switch, rollback points
- Feature flags: on/off, cohort targeting, dependent flags
- SLO context: error‑budget burn, critical paths, recent incidents
A practical pre‑/during‑/post‑deploy policy
Before deploy (prepare)
- Temporarily raise sampling for critical paths to increase metric resolution.
- Switch thresholds to “release‑phase curves” to reduce noise from short spikes.
- Pre‑warm runbooks: prepare diagnostics (dependency health, slow queries, hot keys, thread stacks).
During deploy (canary/blue‑green)

- Fire strong alerts only on “canary cohort” SLO funnels; compare “control vs canary.”
- At traffic shift points, temporarily raise sampling and log levels to capture root causes.
- Define guard conditions (error rate↑, P95↑, success↓, funnel conversion↓) to auto‑rollback or degrade.
After deploy (observe and converge)
- Gradually return to steady‑state sampling/thresholds; keep short‑term focus on critical paths.
- Fold “release events + metrics + alerts + actions” into one timeline for review and learning.
Incident folding and timeline: stop alert storms
- Fold multi‑source signals of the same root cause (DB jitter → API 5xx → frontend errors) into a single incident.
- Attach release context (version, traffic split, feature flags) to the incident for one‑view investigation.
- Record diagnostics and repair actions on the same timeline for replay and continuous improvement.
Ship it with Tianji
- Unified Feed aggregates checks, metrics, and events; fold by timeline: see Feed State Model and Channels.
- Lightweight server status reporting: get key host metrics in minutes: see Server Status Reporter.
- Open telemetry: product/app events capture release context: see Telemetry Intro and Website Tracking Script.
- Custom monitors and synthetic flows on critical paths with policy‑based sampling and automated actions: see Custom Script Monitor.
Implementation checklist
- Map critical paths and SLOs; define “release‑phase thresholds/sampling” and guard conditions
- Ingest release context (version, traffic split, flags, cohorts) as labels on events/metrics
- Build “canary vs control” dashboards and delta‑based alerts
- Auto bump sampling/log levels at shift/rollback points, then decay to steady state
- Keep a unified timeline of “signals → actions → outcomes”; review after each release and codify into runbooks
Closing

Release‑aware monitoring is not “more dashboards and alerts,” but making “releases” first‑class in monitoring and automation. With Tianji’s unified timeline and open telemetry, you can surface issues earlier, converge faster, and keep human effort focused on real judgment and trade‑offs.