Avoiding Cascading Failures: Third‑party Dependency Monitoring That Actually Works
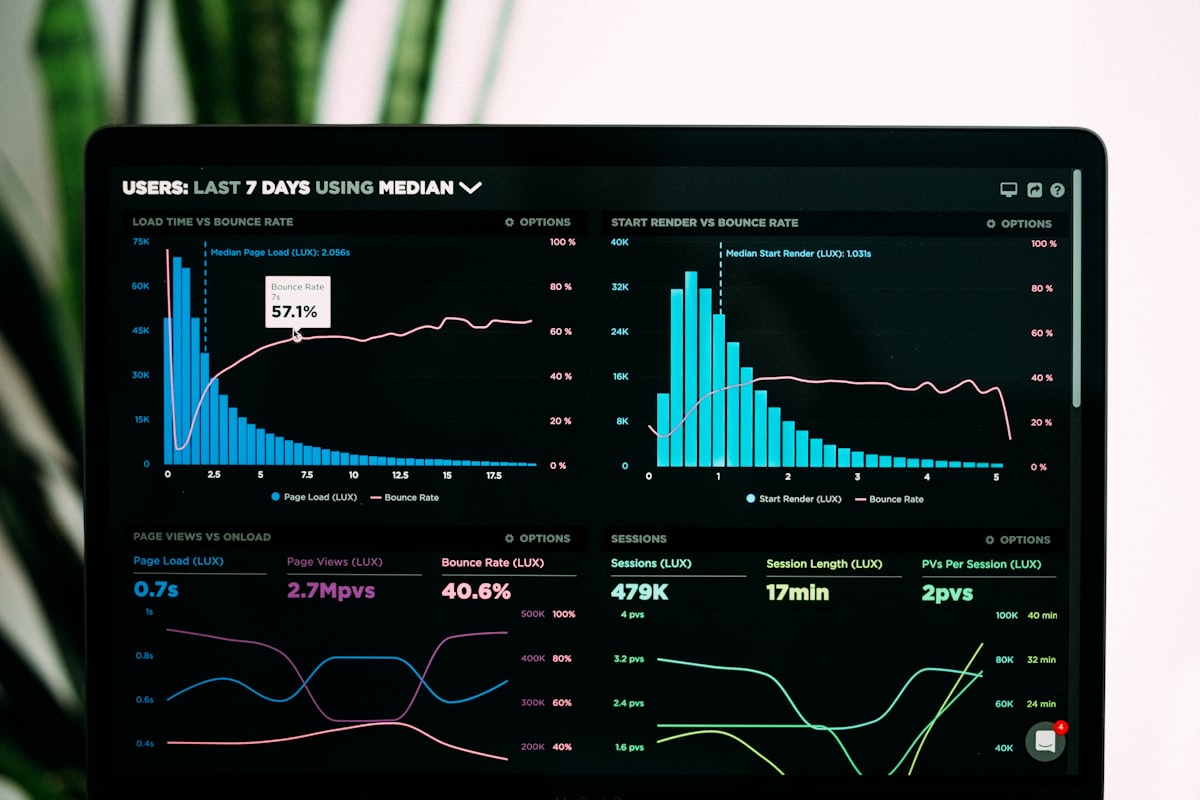
Third‑party dependencies (auth, payments, CDNs, search, LLM APIs) are indispensable — and opaque. When they wobble, your app can fail in surprising ways: slow fallbacks, retry storms, cache stampedes, and silent feature degradation. The goal is not to eliminate external risk, but to make it visible, bounded, and quickly mitigated.
This post outlines a pragmatic approach to dependency‑aware monitoring and automation you can implement today with Tianji.
Why external failures cascade
- Latency amplification: upstream 300–800 ms p95 spills into your end‑user p95.
- Retry feedback loops: naive retries multiply load during partial brownouts.
- Hidden coupling: one provider outage impacts multiple features at once.
- Unknown blast radius: you discover the topology only after an incident.
Start with a topology and blast radius view
Build a simple dependency map: user flows → services → external providers. Tag each edge with SLOs and failure modes (timeouts, 4xx/5xx, quota, throttling). During incidents, this “where can it hurt?” view shortens time‑to‑mitigation.
With Tianji’s Unified Feed, you can fold provider checks, app metrics, and feature events into a single timeline to see impact and causality quickly.
Proactive signals: status pages aren’t enough

- Poll provider status pages, but don’t trust them as sole truth.
- Add synthetic checks from multiple regions against provider endpoints and critical flows.
- Track error budgets separately for “external” vs “internal” failure classes to avoid masking.
- Record quotas/limits (req/min, tokens/day) as first‑class signals to catch soft failures.
Measure what users feel, not just what providers return
Provider‑reported 200 OK with 2–3 s latency can still break user flows. Tie provider metrics to user funnels: search → add to cart → pay. Alert on delta between control and affected cohorts.
Incident playbooks for external outages

Focus on safe, reversible actions:
- Circuit breakers + budgets: open after N failures/latency spikes; decay automatically.
- Retry with jitter and caps; prefer idempotent semantics; collapse duplicate work.
- Progressive degradation: serve cached/last‑known��‑good; hide non‑critical features behind flags.
- Traffic shaping: reduce concurrency towards the failing provider to protect your core.
How to ship this with Tianji
- Unified Feed aggregates checks, metrics, and product events; fold signals by timeline for clear causality. See Feed State Model and Channels.
- Synthetic monitors for external APIs and critical user journeys; multi‑region, cohort‑aware. See Custom Script Monitor.
- Error‑budget tracking per dependency with burn alerts; correlate to user funnels.
- Server Status Reporter to get essential host metrics fast. See Server Status Reporter.
- Website tracking to instrument client‑side failures and measure real user impact. See Telemetry Intro and Website Tracking Script.
Implementation checklist
- Enumerate external dependencies and map them to user‑visible features and SLOs
- Create synthetic checks per critical API path (auth, pay, search) across regions
- Define dependency‑aware alerting: error rate, P95, quota, throttling, and burn rates
- Add circuit breakers and progressive degradation paths via feature flags
- Maintain a unified incident timeline: signals → mitigations → outcomes; review and codify
Closing

External dependencies are here to stay. The teams that win treat them as part of their system: measured, bounded, and automated. With Tianji’s dependency‑aware monitoring and unified timeline, you can turn opaque third‑party risk into fast, confident incident response.




